Q6.) What is the main purpose of Servlet Engine? What does it exactly do in how? What happened to it in AEM 6.0?
Servlet Engine acts as the server within which each CQ (and CRX if used) instance runs as a web application. Any Servlet Engine supporting the Servlet API 2.4 (or higher) can be used.
Although you can run CQ WCM without an application server, a Servlet Engine is needed. Both CRX, and therefore CQ WCM, ship with Day’s CQSE (CQ Servlet Engine), which you can use freely and which is fully supported.
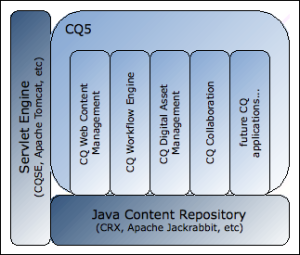
In AEM 6.0 , the CQSE servlet engine has been replaced with Eclipse Jetty .
Q7.) How would you set up an AEM environment from scratch? what will be your choice from IDE to Version manager, Build tools, Integration tool and why?
Installation & Setup: Generally, when you set up Adobe Experience Manager (AEM), you need to set up an Author and a Publish instance. Installation procedures for these are described below:
- On the host file system, create a directory and name it author / publish.
- Copy the cq5-<version>.jar file into author/publish folder and rename it to cq5-autho-p4502.jar / cq5-publish-p4503.jar
- Copy a valid license.properties in the above folder.
- Start AEM Quickstart using one of the following methods:1- If using a GUI file-system explorer, double-click the cq5-publish-p4503.jar file.
2- If using the command line, for a 32bit VM type:java -Xmx1024M -jar cq5-publish-p4503.jar
Or, for a 64bit VM, type:
java -XX:MaxPermSize=256m -Xmx1024M -jar cq5-publish-p4503.jar
3- Use a custom script located in the crx quickstart folder, such as start.bat to start AEM.
The Start and Stop scripts are for UNIX, Linux, and Macintosh. The start.bat and stop.bat scripts are for Windows.
You cannot use a custom script when you install the AEM quickstart jar file (the first time it is started) unless you expand the file first. Use the -unpack option on the command line to unpack the contents before running the script as in java -jar cq5-publish-p4503.jar -unpack.
IDE: Although there are quite a few IDE present for CQ5 development, there are a few which stood out. Here is the list:
- Eclipse is open source software used to edit the project source locally on your file system. Apache Maven is also open source software, used to run local snapshot builds: it compiles Java code and stores the compiled code in a jar file. These days there are quite a bit of plugin specific to AEM
- IntelliJ IDEA 11: A more powerful IDE, has more comprehensive language support out of the box and is much more user-friendly than Eclipse. Read More about it .
- CRXDE: This was which Day supported earlier, but it’s in decline these days. CRXDE and CRXDE Lite don’t support a robust Software Development LifeCycle (SDLC) as they lack a lot of the tools of a full-fledged IDE. Some of the things which are a lot more difficult or not supported by these tools are:
- Releases – You’ll have to create releases manually using the package manager, which leads a lot more room for error, Maven + Eclipse allows for automatic releases
- Source Control Management – They only support SVN and the integration is rather primitive compared to a full IDE
- Continuous Integration – CRXDE and CRXDE Lite don’t use build scripts which can be invoked by a CI server, you’ll have to create them separately, in a real IDE, both the IDE and CI server can use the same
- Java Development – Java development through CRXDE seems to take second fiddle to JSP development. In my experience, this leads to sites build with business logic scattered throughout a labyrinth of messy JSP code. A much better approach is to use an IDE which makes writing and maintaining Java Services easy and efficient.
Among the three above, these days Eclipse is the one which is widely used and accepted as many people are quite familiar with it and it supports the development of AEM based applications too. However, IntelliJ is new and yet to be explored.
Version manager: The most common versioning control systems for the Java ecosystem:
- Subversion (SVN), as a representative model of centralized version control
- Git, as representative of the distributed model
You may choose any one of the above, based on the use case for your requirement. Below are the major differences between the two:
- GIT is distributed, SVN is not: This is by far the *core* difference between GIT and other non-distributed version control systems like SVN, CVS etc. GIT like SVN does have centralized repository or server. But, GIT is more intended to be used in the distributed mode which means, every developer checking out code from central repository/server will have their own cloned repository installed on their machine. Let’s say if you are stuck somewhere where you don’t have network connectivity, like inside the flight, basement, elevator etc. :), you will still be able to commit files, look at revision history, create branches etc. This may sound trivial for a lot of people but, it is a big deal when you often bump into the no-network scenario.
And also, the distributed mode of operation is the biggest blessing for open-source software development community. Instead of creating patches & sending it thru emails, you can create a branch & send a pull request to the project team. It will help the code stay streamlined without getting lost in transport. GitHub.com is an awesome working example of that. - GIT stores content as metadata, SVN stores just files: Every source control systems stores the metadata of files in hidden folders like .svn, .cvs etc., whereas GIT stores entire content inside the .git folder. If you compare the size of .git folder with .svn, you will notice a big difference. So, the .git folder is the cloned repository in your machine, it has everything that the central repository has like tags, branches, version histories etc.
- GIT branches are not the same as SVN branches: Branches in SVN are nothing but just another folder in the repository. If you need to know if you had merged a branch, you need to explicitly run commands like svn propget svn:mergeinfo to verify if it was merged or not. So, the chance of adding up orphan branches is pretty big. Whereas, working with GIT branches is much easier & fun. You can quickly switch between branches from the same working directory. It helps to find un-merged branches and also help to merge files fairly easily & quickly.
- GIT does not have a global revision no. like SVN does: This is one of the biggest features I miss in GIT from SVN so far. As you may know already SVN’s revision no. is a snapshot of source code at any given time.
- GIT’s content integrity is better than SVN’s: GIT contents are cryptographically hashed using the SHA-1 hash algorithm. This will ensure the robustness of code contents by making it less prone to repository corruption due to disk failures, network issues etc.
Build tools:
Apache Maven is an open source tool for managing software projects by automating builds and providing quality project information. It is the recommended build management tool for AEM projects.
Building your AEM Project based on Maven offers you several benefits:
- An IDE-agnostic development environment
- Usage of Maven Archetypes and Artifacts provided by Adobe
- Usage of Apache Sling and Apache Felix toolsets for Maven-based development setups
- Ease of import into an IDE; for example, Eclipse and/or IntelliJ
- Easy integration with Continuous Integration Systems
Integration Tools: These days more and more software companies are adopting Continuous integration (CI). It is a software engineering practice in which isolated changes are immediately tested and reported on when they are added to a larger code base. The goal of CI is to provide rapid feedback so that if a defect is introduced into the code base, it can be identified and corrected as soon as possible.
Popular open source tools include Hudson, Jenkins (the fork of Hudson), CruiseControl and CruiseControl.NET. Commercial tools include ThoughtWorks’ Go, Urbancode’s Anthill Pro, JetBrains’ Team City and Microsoft’s Team Foundation Server.
You may go for Jenkins instead of Hudson because of the following reasons:
- Led by developers for developers: The developers who wrote 99% of the core of Hudson are now working on Jenkins, including Kohsuke Kawaguchi, the original creator. He wrote the majority of code single-handedly and his range of expertise was a key enabler in various advanced features of Hudson.
- Governance and Community: The community managing the Jenkins project is very open. There is an independent board that includes longtime Hudson developers from multiple companies including Yahoo!, CloudBees, Cloudera, and Apture. They hold regular governance meetings and post notes after each meeting for public comment.
- Stability: As we see the increase in the contributions to Jenkins, more than 280 tickets have closed since the split, and Jenkins has started a new long-term support release line. The community has decided to announce a stable release approximately every three months with patches. Lastly, Jenkins posted its first release 1.409.1, which provides a more conservative and slower upgrade path to organizations
- Jenkins is the primary platform for plug-Ins: Jenkins currently supports 392 plug-ins. Of the top 25 plug-ins, 21 moved to Jenkins and four had no commits. Plus, there have been 40 new plug-ins since the split. With such powerful and diverse functionality, Jenkins is the hub of the new application development lifecycle.
- Jenkins is cloud-enabled: One of the core needs of Jenkins users is the lack of resources during peak periods. CloudBees provides a solution with DEV@cloud, providing developers with Jenkins build, test, and packaging services as well as unlimited, pay-as-you-go scalability with no need to configure and maintain their own build servers.
Q8.) Imagine you have a dynamically updated XML file stored at /var/yourlocation , which contains all the user profile information. You have to store that profile data from the XML file in /etc/yourlocation/nodeX….structure (where X could be 1, 2, 3….and so on). How will you proceed to design this in the best possible manner?
To approach this use case we will divide the problem into a few technical steps:
1. The first thought which should come up in your mind should be how to handle the dynamic addition of the XML file at this location. There can be two approached to achieve this –
- Event Handlers.
- Workflow activated by a Launcher.
The better approach would be to use Event Handler which will listen to any modification of that particular node /var/yourlocation .
2. Inside that event handler onEvent() method, you may write your custom code to pick that XML file and apply a DOM parser. This would help in resolving the known XML file and fetch the properties and nodes from it. There is a good way to do it here.
3. The properties and nodes fetched from the DOM parser can be used to create nodes under the /etc/yourlocation/nodeX location as per the question demands. Now the trick is how to design to create nodes. You should be utmost optimal while creating more than 1000 nodes. Please read Q4) above for complete solution to that.
Q9. )In reference to above question, imagine the Nodes are way too many now under /etc/yourlocation and every node created 30 days before should be purge (deleted). How will you proceed to design that solution?
Here there is a need for a periodic task/job purging which needs to be done. So you need to write a scheduler for the requirement. The approach you may follow here is that you should fire a Query to list down all the nodes where jcr:created property value is before the 30days from the Server Date. Fetch all the resultant nodes and delete the nodes accordingly.
The catch here is that how you delete a node. If you will initiate a loop and perform a delete and save session (at JCR ) operation simultaneously, that would be quite cumbersome for the JVM and the system might slow down when your scheduler executes. Not at all advisable to do.
The better approach for Purging a large number of nodes would be to follow the below-mentioned approach:
if (toBeRemoved) {
node.remove();
counter++;
if (counter > 500) {
log.info("500 deleted nodes reached, persisting...");
session.save();
counter = 0;
}
}
By this approach, you are hitting the JCR for a delete operation on every 500 or 100 nodes as per need. This would decrease the burden alot.
Q10. ) You have to create a Global page where admin users can see all the CQ-users who didn’t log-in since 30/60/90 days (take a drop-down). On that page, there should be an option (checkbox) to delete the specific user as per the need of admin. Your task is to design a solution for this use case.
This seems to be an easy one, but it’s quite a tricky question. You have to search the list of all the users who didn’t log in 30 or 60 or 90 days prior to the search date. I approached this question in the following way:
- As the dropdown is having a parameter days (30/60/90), you should use an ajax calling a Servlet (let’s say /bin/adobe/cqusers) . This servlet will pick up two parameters — days and function (“list” or “delete”). Now on the basis of the passed parameters in ajax call, you may write two methods– userList() and deleteUsers().
- Now the problem would come up how will you get the list of users who didn’t accessed the site for N number of days. If you will check the user profile, there is no property which tells you that criteria. So the only way out is to set a property (let’s say lastAccessedDate). This property is updated every time a user logs into the site and using this property we can fire a query which will help you get the user-list.
- You may override the Authentication Handler for setting this property lastAccessedDate as current Date whenever a user logs in the application.

Pingback: How to Prepare ? – CQ5 AEM Tricks of Trade
I have one question for the migration of the Page content versions to new instances/upgrade to higher version of AEM.
As per the documentation from the Adobe are we going to lose the versions. ?
https://docs.adobe.com/docs/en/cq/5-6-1/core/administering/backup_and_restore.html#Package%20Backup
I am trying to retain my page content versions authored data when migrating to another instance. Tried via the package manager but getting error like below
” /jcr:system/jcr:versionStorage/b7/c0/80 (javax.jcr.PathNotFoundException: 80)
saving approx 3 nodes…
Package imported (with errors, check logs!) ”
Is there any chance for retaining page versions via the API.
Note :- I cannot go for an in-place upgrade, as i have AEM Instance A with some set of applications and another AEM instance B with different set of applications and planning a migration to AEM instance C
LikeLiked by 1 person
Hi Vardhan,
If you want to transfer content along with the Versions you may try to package out the version Nodes using the Filter option of Package Manager. If the number of versions are huge and the packages doesnt work due to that, try to version purge some older versions and then try to package out.
Even after that if the package fails, please post the error logs here .
Regards
Hashim
LikeLike
Thank you Hashim,
when i tried taking a package and install in another instance able to see the following error.
” Importing content…
– /
– /content
– /content/geometrixx
– /content/geometrixx/en
– /content/geometrixx/en/products
– /content/geometrixx/en/products/triangle
– /content/geometrixx/en/products/triangle/features
U /content/geometrixx/en/products/triangle/features/jcr:content
– /content/geometrixx/en/products/triangle/features/jcr:content/par
– /content/geometrixx/en/products/triangle/features/jcr:content/rightpar
A /content/geometrixx/en/products/triangle/features/jcr:content/title
– /content/geometrixx/en/products/triangle/features/jcr:content/par/image
– /content/geometrixx/en/products/triangle/features/jcr:content/par/table_0
– /content/geometrixx/en/products/triangle/features/jcr:content/rightpar/iparsys_fake_par
– /jcr:system
– /jcr:system/jcr:versionStorage/b7/c0
E /jcr:system/jcr:versionStorage/b7/c0/80 (javax.jcr.PathNotFoundException: 80)
saving approx 3 nodes…
Package imported (with errors, check logs!)
Package installed in 662ms. “
LikeLike
Hi ,
I believe some of the version nodes are corrupted in your existing environment. Try two things:
1. Are you able to install the package in another environment of same configuration and version
2. Try to exploit VLT tool and checkout the versions using that. Then use vlt to checkin the nodes in your new instance.
3. If all this fails, then try to run a consistency check on the version nodes.
Do let me know what are your findings. Hopefully it should work.
Regards
Hashim
LikeLike
Pingback: AEM Useful Links – enlightenmyknowledge
How to Access versioning in publish instance
LikeLike
Hi , I didnt get the question. Why do you want to Access a version of a page in Publish instance. Versions are stored in Author and the final verified version is Pushed to Publish.
LikeLike
thanks for replay Hashim Khan
when publish page, we are able to generate versions in jcr:system level in author instance but i need to generate versions data in publish instance..
i am able to create versions digital assets in publish instance for this i change workflow launcher (dam metadata writeback) runmodes publish to author,publish.
how can we do versioning for pages in publish instance ?
LikeLike
I would say it doesn’t seem to be a good idea to create Versions on Publish instance due to the reason as Author has all the versions and its not good to clutter the Publish instance with versions. But still if you must need it, you can probably use Page Manager API.
https://docs.adobe.com/docs/en/aem/6-1/ref/javadoc/com/day/cq/wcm/api/PageManager.html
LikeLike
thanks, i able to create versions in publish instance
LikeLiked by 1 person
Hi HashimKhan
How to activate Page with out create versionHistory data Jcr:system Level
/jcr:system/jcr:versionStorage/b6/7f/7c/b67f7c22-678f-4696-9022-80a21665aed5/1.0
i don’t want create versions like 1.0, 1.1,1.2….. when i am activate page
Because I am already using create Version workflow by using this i am generating version data 1.0,1.1…..
LikeLike
You can try to disable the versioning https://helpx.adobe.com/experience-manager/kb/DisableVersioning.html
LikeLike
thanks for reply
in My workflow i have two models 1)create version model 2) activate page workflow
by create version workflow i am creating versions like 1,0,1,,1,1,2 this one is fine.
again i m using activation page model to activate page author to publish instance.
in that it will creating versions 1,0,1,,1,1,2…….. i don’t need to create versions in this model.
in workflow only one time i need to create versions .
is it possible particular activate page model i need to disable versions.
LikeLike
com.day.cq.wcm.core.impl.VersionManagerImpl in this osgi configuration
versionmanager.createVersionOnActivation (Boolean, : false)
i am not able to create versions
how to do for specific project this configuration
i don’t want affect this configuration remaining projects
LikeLike
i approached another process, my problem is solved
Thank you
LikeLike
Do let us know how you approached the problem. Thanks
LikeLike
i am not using pageActivation Model in Workflow
i am create versions by using createVersion Model then Assign that version in to etc/test/node properties
As per coding just replicating etc/test/node to publish instance
replicator.replicate(session, ReplicationActionType.ACTIVATE, etc/test/node );
my project requirement we don’t need to activate pages.
LikeLike
com.day.cq.wcm.core.impl.VersionManagerImpl in this osgi configuration
versionmanager.createVersionOnActivation (Boolean, : true )
Is it Possible how to do for specific project this configuration
versionmanager.createVersionOnActivation (Boolean, : false )
i don’t want affect this configuration remaining projects
LikeLike
Pingback: Your Complete Guide for Passing Adobe Experience Manager (AEM) 6 Architect Certification (9A0-385) Exam
Hi Hashim,
I am new to the AEM. Just wandering usually we deploy the WAR files to the application server in J2EE projects. How we will create a PROD or other high level environment for AEM. Is there is any recommended practice from Adobe?
LikeLike
HI, Yes there are a lot of Best Practices https://helpx.adobe.com/experience-manager/6-3/sites/developing/using/best-practices.html
LikeLike
Hi Hashim, Where can I check my dam is pointing to which environment? like DEV,STG and Prod ?
LikeLike